

Data Tagging and Classification


Data tagging is a priority objective, critical to the ability to both locate information and enable automated access control decisions. This document articulates the minimum functional requirements of data tagging standards needed to facilitate interoperable Discovery, Access Control, Correlation, Audit, and Records Management capabilities across any data platform.
Data “tags” are metadata—“data about data” applied to resources. A “tag” is an assertion describing some aspect of a resource, pairing a semantic label (or “tag name”) with a corresponding tag value. For example, a document may be tagged with Language=“English”. The tag consists of both the name and the value, illustrated below. What Is a Tag? The idea of metadata is not new—files have had rudimentary metadata (e.g., size, name, or date) since the early days of computer systems. Data tags extend this concept into a far richer set of metadata.
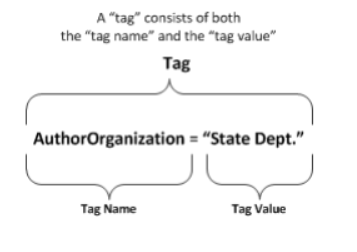
A Typical Example
A Real world scenario is helpful to illustrate how using data tagging and access policies will determine data access privileges. Very typical in the Healthcare industry, where we want to grant a end user the ability to access data that has been tagged with a Payer value of AcmeHealth. The desired result is that only AcmeHealth data is returned by the role querying a table (for our example, we will call it payer_data; other data the payer_data table, where Payer is ChiHealth or UpHealth, should not be returned
Operational Context
While data tags can be used for any number of purposes and can support any number of capabilities, this framework is oriented around five capabilities common across a data platform that are essential to information classification and safeguarding
Query and Discovery: the ability to locate and obtain knowledge of the existence of, but not necessarily the contents of, a resource
Access Control: granting or denying specific requests for resources based on a defined set of criteria
Correlation: identifying relationships between entities within and across disparate data sets
Audit: recording the sequence of actions surrounding or leading up to a specific activity or event
Records Management: operational activities involved with the creation, retention, and disposition of records
This data tagging framework takes a three-tier hierarchical approach to data tags:
1) Tag Area: an abstract, purely administrative grouping of tags that support a common capability.
This framework has developed the following Tag Areas:
Resource Description: Tag Classes that contribute to a requestor being able to locate a resource, akin to a card in a library card catalog
Reference: Tag Classes that contribute to linking a resource with other related resources; akin to a bibliography
Safeguarding and Sharing: Tag Classes that contribute to understanding who may access (either for discovery or retrieval purposes) a resource, how it may be used, and how to properly protect the resource
2) Tag Class: a logical, well-defined concept, the meaning of which is consistent across organizations (that is, it is “portable”) but is still abstract.
3) Tag: the concrete syntactic and semantic means and encodings defined by a data asset to realize the concept described by a Tag Class. Tags, and the specifications that formally describe them
Tags are the first and only concrete layer in the tiered tagging construct, and consist of a name+value pair that together convey some information about the resource with which the tag is associated. One or more tags may combine to provide the information required by a Tag Class. In our healthcare scenario, the Tag Class, “Concepts” for Member or Medical categories can contain multiple “Payer” tags.
Both the single-tag and multiple-tag authorship models described above are acceptable under this decentralized-yet-compatible framework. As data teams define their tagging specifications (or adopt an existing tagging specification), the tags map back to the Tag Class that they support, enabling construction of machine-readable rules to perform automated translation.
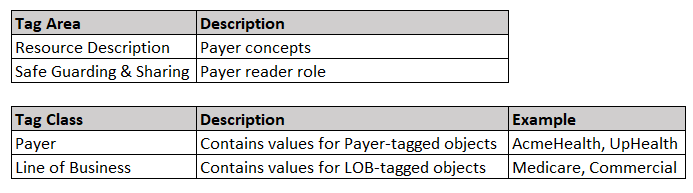
Note the Safe Guarding & Sharing tag area — this is the critical piece of information we will need when we define the row access policies later. Using the Tag Area, we can identify the access controls needed to determine who can access the data, and how they are allowed to access it.
Snowflake Implementation
Create Object Tags
Now that we have determined the tag classification scheme for our data, it is time to implement tags on Snowflake objects. You can set a tag on a Snowflake object with the create <object> or alter <object> statement. You can find the complete list of supported objects here: Object Tagging — Snowflake Documentation.
A single tag can be assigned to multiple objects at the same time. From our healthcare scenario, we may wish to assign the Payer tag to a few databases that each may have tables that store this type of data.
Since tags can be assigned to database objects like tables, columns, etc., setting a tag and then querying the tag will allow us to determine how to make the data available using row access policies.
Create Tags for Payer and LOB
-- Create a custom tag role and assign both CREATE and
-- APPLY privileges. Essentially, the new role will be responsible
-- for centrally managing our tags.
use role useradmin;
create role tag_admin;
grant role tag_admin to role sysadmin;
use role accountadmin;
grant create tag on schema prod.cdr to role tag_admin;
grant apply tag on account to role tag_admin;
-- Grant the custom tag role usage on the database, schema,
-- and warehouse.
grant usage on database prod to role tag_admin;
grant usage on schema prod.cdr to role tag_admin;
grant usage on warehouse wh_small to role tag_admin;
-- Create new tags.
use role tag_admin;
use schema prod.cdr;
create tag payer
allowed_values 'AcmeHealth','ChiHealth','UpHealth';
create tag line_of_business
allowed_values 'Medicare','Medicaid','Commercial';
-- Assign new tags to objects; in this example, we will assign
-- the tags to an existing table.
alter table prod.cdr.payer_table
set tag payer = 'AcmeHealth';
alter table prod.cdr.payer_table
set tag line_of_business = 'Commercial';
-- Discover the tags we just created.
select * from snowflake.account_usage.tags;
-- List the tag's values.
select system$get_tag('payer', 'payer_table', 'table');
Define Row Access Policies
Row access policies are schema-level objects that implement row-level security to determine which rows can be accessed by queries using SELECT, UPDATE, DELETE, or MERGE statements.
This approach supports the segregation of activities that allow organizations to define limits to sensitive data. This includes the OWNERSHIP privilege on an object, that normally has full access to the data.
Different policies can be set on different tables or views at the same time and can be added at the time the object is created, or after the object has been created. Snowflake evaluates a policy expression by using the role of the policy owner (not the operator who executes a query), allowing Snowflake not to return a row in a query result because the operator does not require access to the mapping tables in the row access policy.
Snowflake goes through the following steps to implement row access policies on objects:
Determine whether a row access policy is set on an object; if one exists, all rows are covered by the policy.
Snowflake creates a dynamic secure view of a database object.
Values of the columns in the ALTER TABLE or ALTER VIEW command are bound to the corresponding policy parameters; the policy expression is evaluated.
Snowflake generates the query output; only rows based on the policy are returned.
Row access policies should derive from user policies, in that the broader organization defines what should or should not be accessible to various groups.
For example, if the organization wants to allow only users belonging to the AcmeHealth_Read role to view data associated with AcmeHealth, and no others, then we can do this:
create or replace row access policy acmehealth as (market_id varchar) returns boolean -->
'acmehealth_read' = current_role()
;
The above example allows users in the role to query a market identification number before updating the table. Therefore, the row access policy will return rows only if the result of the CURRENT_ROLE() matches the AcmeHealth_Read role and does not return rows for all other roles.
The policy is the most concise version of a row access policy because there are no other conditions to evaluate; only the value of CURRENT_ROLE(). Using CASE function allows WHEN/THEN/ELSE clauses to support conditional logic for additional conditions.
To apply the row access policy we created, we can just execute the following statement:
alter table payer_table add row access policy acmehealth on (market_id);
For a new table, provider, we can apply the policy at the time the table is created:
create or replace row access policy providerhealth as (provider_specialty varchar) returns boolean -->
'acmehealth_read' = current_role()
;
create table provider (
provider_id varchar,
provider_name varchar,
provider_address varchar,
provider_specialty varchar
)
with row access policy providerhealth on (provider_specialty);
-- View an existing policy
select *
from table(prod.information_schema.policy_references(
policy_name=>'acmehealth'
)
);
-- For a policy assigned to a specific object, you can execute the
-- following stmt
select *
from table(prod.information_schema.policy_references(
ref_entity_name => 'payer_table',
ref_entity_domain => 'table'
)
);
For additional information on limitations and considerations, you can consult the documentation here: https://docs.snowflake.com/en/user-guide/security-row-intro.html.
Associate Tags to Access Policies
There are many ways in which to provision the actual policies using the tagging meta-data we have created. Albeit, levering automatic classification strategies, auto-detection of various PHI/PII, to illustrate a simple example, we use a mapping table and apply a CI/CD like approach provisioning RBAC. This table will store the information we captured in our meetings with the rest of the organization. The grain of the table will be the database, schema, table, column to secure, role, or object tag.
Based on these values, we assign a row access policy and associate the policy with the user role in Snowflake.
create or replace tag_role_mapping (
tag_name varchar,
tag_value varchar,
db_name varchar,
schema_name varchar,
table_name varchar,
secure_column varchar,
role_name varchar
);

Since the mapping table has privileged information that allows setting up row access policies and role privileges, we will want to store it in a secure database and schema that only a role with security privileges is allowed to query:
use role securityadmin;
create or replace role mapping_role;
grant role mapping_role to role sysadmin;
-- Grant privileges to new role.
grant select on table security.admin.tag_role_mapping to mapping_role;
grant usage on database admin to role mapping_role;
grant usage on schema admin.security to role mapping_role;
-- Additional privileges on the row access policy.
grant ownership on row access policy admin.security.providerhealth to role mapping_role;
grant apply on row access policy admin.security.providerhealth to role mapping_role;
-- Create a new row access policy which uses the mapping table
create or replace row access policy admin.security.providerhealth as (specialty varchar) returns boolean ->
'acmehealth_read' = current_role()
or exists (
select 1 from tag_role_mapping
where role_name = current_role()
and provider_specialty = specialty
);
-- If we want the new role to apply to the providerhealth row access
-- policy, add the following
alter table prod.provider_table add row access policy providerhealth on (provider_specialty);
-- Grant privelege on the protected table to the role
grant select on table prod.provider_table to role acmehealth_read;
At runtime, Snowflake will determine whether the user executing the query matches the role mapped to the market; anyone with membership in the acmehealth_read role, can successfully retrieve data from the provider_table. On the other hand, even if we grant another role such as business_reader access to the table, the query will not return any rows.
More complicated implementations, which we will post later, include leveraging a "gitops" methodology where any changes to a repo storing the related tagging meta-data is changed, a CICD approach dynamically makes Snowflake look exactly like whats in github.